
As the Internet of Things (IoT) landscape continues to grow, practically everyone and everything, it seems, is compiling data or at least generating statistics for any variable imaginable. And music is no exception. The music streaming service, Spotify, stores an array of features for each song in its library. They record characteristics such as acousticness, danceability, energy and more. With these variables in mind, I conducted some exploratory analysis along with a couple clustering methods on Kanye West’s Spotify discography. The following report utilizes Spotify’s Web API through Charlie Thompson’s spotifyr package which you can check out here.
Exploratory Data Analysis
Load Packages
The following code and plots make use of these packages:
library(spotifyr)
library(tidyverse)
library(knitr)
library(kableExtra)
library(ggridges)
library(plotly)
library(scales)
library(ggfortify)
library(ggdendro)
library(dendextend)Import Data
First let’s import the audio features for Kanye West and take a quick look at the data.
kanye <- get_artist_audio_features(artist = "kanye west")After viewing the data, I noticed a few tracks (rows) are duplicated since some albums contain edited, clean, and/or live versions. Those rows will be removed in addition to some irrelevant columns. Also let’s be sure we don’t have any missing values.
kanye2 <- kanye %>%
filter(!(album_name %in% c("808s & Heartbreak (Softpak)", "Late Orchestration",
"The College Dropout (Edited)",
"Graduation (Alternative Business Partners)"))) %>%
select(-c(artist_uri, album_uri, album_type, is_collaboration, track_uri,
track_preview_url, album_release_year, artist_name, album_img,
album_release_date, track_open_spotify_url, track_number,
disc_number, key, mode, key_mode, album_popularity, time_signature))
sum(is.na(kanye2))## [1] 0The dataset we will be working with now has 125 rows and 13 columns with no missing observations!
###Danceability Spotify defines danceability as
“How suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.”
Before determining which album Spotify deems the most danceable, let’s take a look at how danceability is distributed on each album.
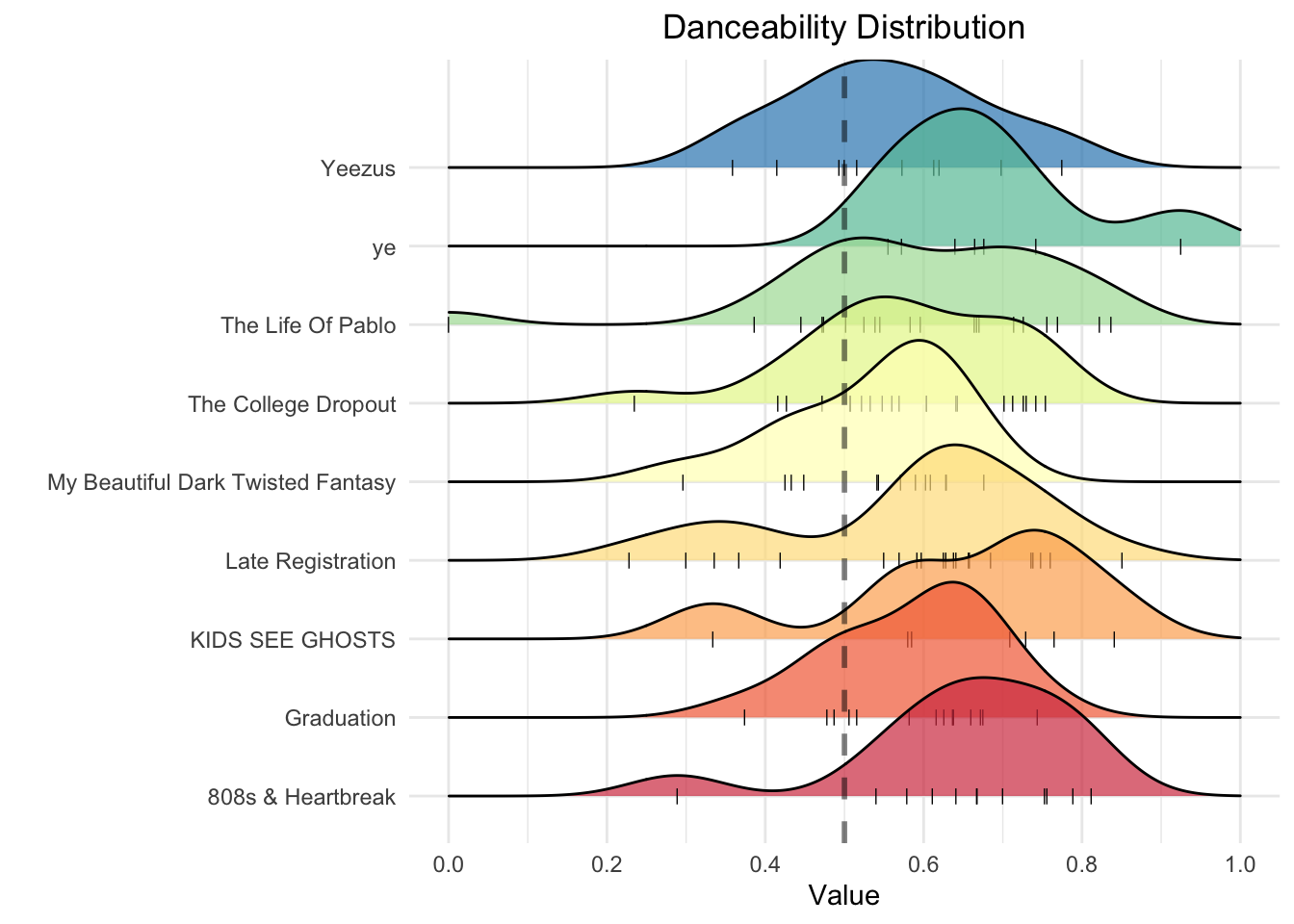
The dashed vertical line in the middle represents the midpoint on the danceability scale. Also, the smaller tick marks at the bottom of each shape represent one song on an album. Each album appears to be more danceable than not, but let’s weight each song by its duration to get a better picture of each album in its entirety. The following graph outlines the results.
kanye_dance <- kanye2 %>%
mutate(total_dance = danceability*duration_ms) %>%
group_by(album_name) %>%
summarise(avg_danceability = sum(total_dance)/length(album_name)/10000)Overall, My Beautiful Dark Twisted Fantasy and 808s & Heartbreak represent Kanye’s most danceable albums. The following table lists his top 10 most danceable songs.
kanye_dance_songs <- kanye2 %>%
arrange(desc(danceability)) %>%
select(album_name, track_name, danceability)
kable(head(kanye_dance_songs, 10)) %>%
kable_styling(full_width = F)| album_name | track_name | danceability |
|---|---|---|
| ye | All Mine | 0.925 |
| Late Registration | Gone | 0.851 |
| KIDS SEE GHOSTS | Kids See Ghosts | 0.841 |
| The Life Of Pablo | Feedback | 0.837 |
| The Life Of Pablo | 30 Hours | 0.822 |
| 808s & Heartbreak | Paranoid | 0.812 |
| 808s & Heartbreak | Heartless | 0.789 |
| Yeezus | Black Skinhead | 0.775 |
| The Life Of Pablo | Facts (Charlie Heat Version) | 0.769 |
| KIDS SEE GHOSTS | 4th Dimension | 0.765 |
Valence
Spotify defines Valence as
“A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry)”"
Again, let’s look at the overall distribution for each album, but for valence this time.
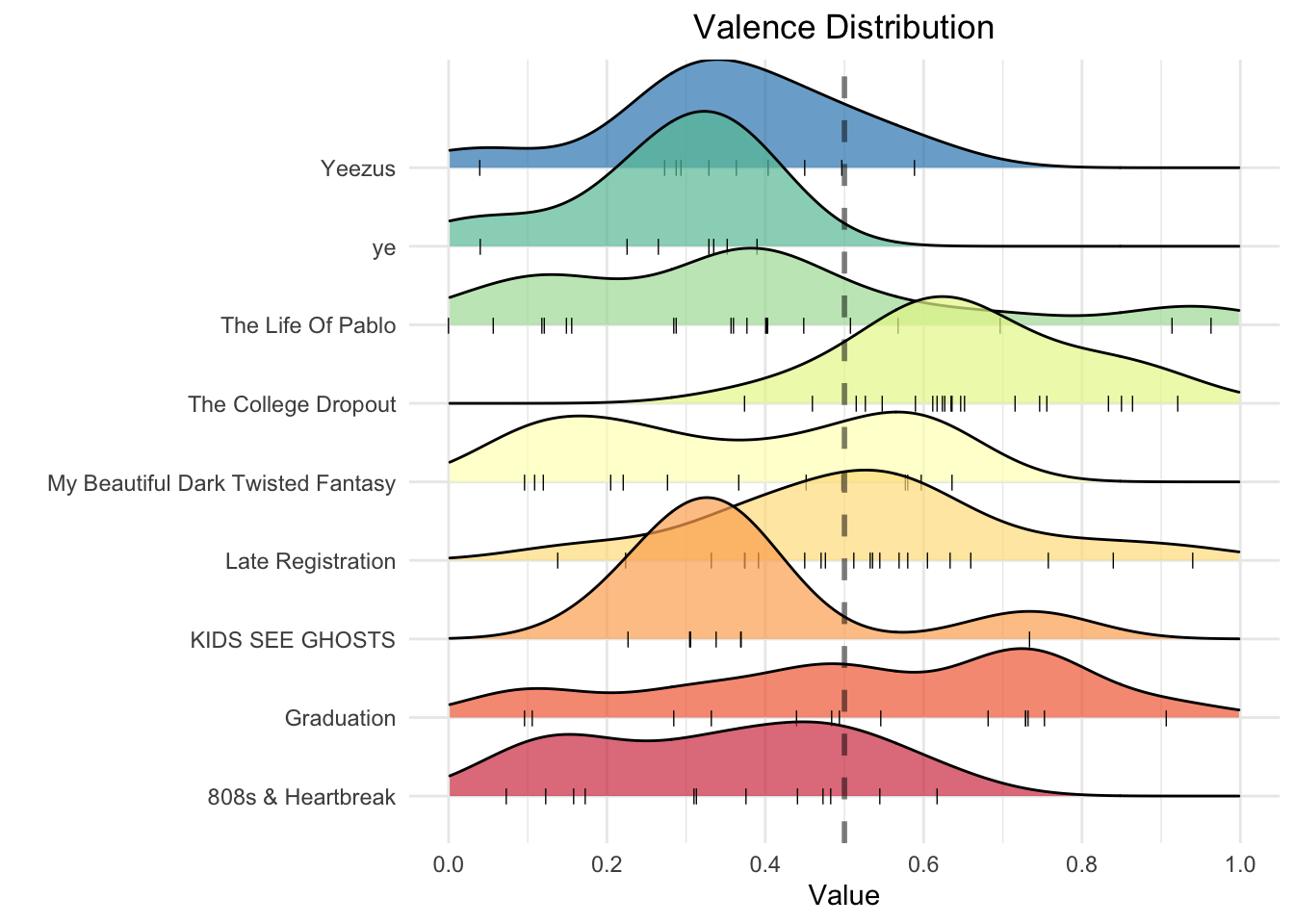
Perhaps a bit more polarizing than the danceability metric, most albums seem to have their fair share of both positive and negative sounding songs. Now weighting valence by song duration, let’s discover Kanye’s happiest (and saddest) album.
kanye_val <- kanye2 %>%
mutate(total_valence = valence*duration_ms) %>%
group_by(album_name) %>%
summarise(avg_valence = sum(total_valence/length(album_name)/10000))With a valence score of 14.68, the happiest Kanye release came way back in 2004 with his debut hit The College Dropout. Interestingly, the four albums with the lowest valence score also make up his most recent work. The tracks with the lowest valence scores are shown below.
kanye_valence_songs <- kanye2 %>%
select(album_name, track_name, valence) %>%
arrange(valence)
kable(head(kanye_valence_songs,10)) %>%
kable_styling(full_width = F)| album_name | track_name | valence |
|---|---|---|
| The Life Of Pablo | Frank’s Track | 0.0000 |
| Yeezus | Hold My Liquor | 0.0399 |
| ye | Violent Crimes | 0.0400 |
| The Life Of Pablo | Waves | 0.0565 |
| 808s & Heartbreak | Welcome To Heartbreak | 0.0734 |
| Graduation | Can’t Tell Me Nothing | 0.0963 |
| My Beautiful Dark Twisted Fantasy | Monster | 0.0964 |
| Graduation | I Wonder | 0.1060 |
| My Beautiful Dark Twisted Fantasy | Runaway | 0.1090 |
| The Life Of Pablo | Wolves | 0.1180 |
Other Variables
Interested in exploring the rest of the variables? Choose which characteristics to plot and select which albums to compare using the interactive graph below!
Clustering
Hierarchical Clustering
Now on to some clustering methods. Let’s determine which albums sound the most alike using hierarchical clustering. A tree with a height of 4 and complete linkage is shown below.
kanye3 <- kanye2 %>%
select(-c(track_name, track_popularity)) %>%
group_by(album_name) %>%
summarise(dance = sum(danceability*duration_ms)/length(album_name),
energy = sum(energy*duration_ms)/length(album_name),
loudness = sum(loudness*duration_ms)/length(album_name),
speechiness = sum(speechiness*duration_ms)/length(album_name),
acousticness = sum(acousticness*duration_ms)/length(album_name),
instrumentalness = sum(instrumentalness*duration_ms)/length(album_name),
liveness = sum(liveness*duration_ms)/length(album_name),
valence = sum(valence*duration_ms)/length(album_name),
tempo = sum(tempo*duration_ms)/length(album_name)) %>%
remove_rownames() %>%
column_to_rownames("album_name")
kanye.hc <- hclust(dist(scale(kanye3)), method = "complete")
kanye.tree <- dendro_data(kanye.hc, type = "rectangle")
kanye.hc.4 <- cutree(kanye.hc, k = 4)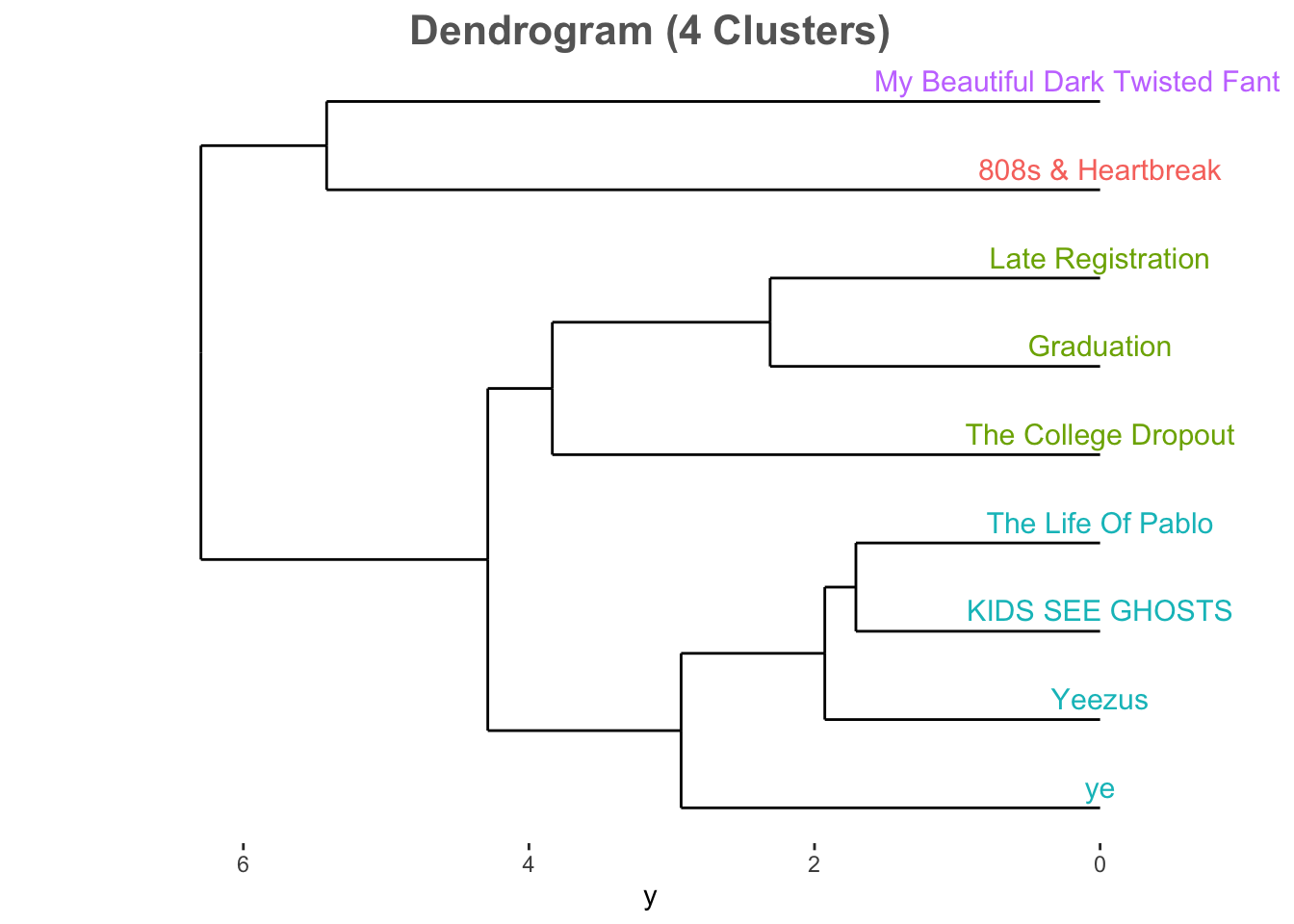
Kanye’s first three releases belong to one cluster while his last four belong to another. The middle releases, 808s & Heartbreak and Twisted Fantasy, are not only his most danceable records but his most unique sounding as well; they each populate their own cluster.
Principle Component Analysis
Now let’s use those variables and see if we can discover if his more popular songs score similarly for each variable. Using a PCA to reduce dimensionality and account for correlation we can try to reveal any patterns.
kanye_pca <- prcomp(kanye2[,3:11], center = T, scale = T)
summary(kanye_pca)## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6 PC7
## Standard deviation 1.5958 1.2793 1.0779 0.9988 0.9512 0.84785 0.69853
## Proportion of Variance 0.2829 0.1819 0.1291 0.1108 0.1005 0.07987 0.05422
## Cumulative Proportion 0.2829 0.4648 0.5939 0.7047 0.8053 0.88513 0.93934
## PC8 PC9
## Standard deviation 0.62701 0.39085
## Proportion of Variance 0.04368 0.01697
## Cumulative Proportion 0.98303 1.00000Using two principle components we can describe a little over 46% of the variability in the data (shown in the plot below). To explain at least 90% of the variability, we need to use 7 principle components. The following graph shows the top two principle components with the top quartile of his most popular songs mapped to one color and the rest to another.
The most popular songs don’t appear to belong to any specific area or cluster on the graph, but it does look like Energy and Loudness are correlated. Try graphing them using the interactive plot above!
